TL;DR
Power sampling elicits reasoning by sampling from a sharpened version of the base model's distribution. We make power sampling more efficient by placing Metropolis-Hastings cuts at key decision points (e.g., the choice of proof strategy or algorithm). This yields a faster mixing time that scales with the number of decisions rather than the number of generated tokens, and empirically it improves reasoning across math, coding, and STEM benchmarks.
Summary
Power sampling is a training-free alternative to RL post-training. Instead of changing the model's weights, it samples from a sharpened version of the base distribution, one that upweights reasoning traces the base model already finds likely. But sampling from this distribution is computationally hard. The standard approach uses Metropolis-Hastings (MH), an MCMC method that proposes candidate edits and accepts or rejects them so that the chain converges to the target. In the stagewise version, each step picks a cut position uniformly at random, resamples the suffix, and applies the accept/reject rule. The trouble is that uniform cuts mostly rewrite "local details" rather than the consequential decisions that determine the reasoning path.
We introduce Entropy-Cut MH, which places cuts at positions where the base model's next-token entropy jumps upward, a cheap proxy for decision points. Crucially, only the proposal changes; the MH correction keeps the target distribution the same. In a stylized reasoning-tree model, this lowers the mixing time from the token depth T to the number of semantic decisions k, which can be much smaller. Empirically, the method improves over standard sampling, low-temperature sampling, SMC, TMC, and uniform-cut MH across MATH500, HumanEval, GPQA Diamond, and AIME26.
Uniform-Cut MH
Cut inside a local calculation
we have x = 0 and y = 3.
Step 1: Calculate r
r = sqrt(x^3 + y^3)
= sqrt(0^3 + 3^3 [CUT])} = sqrt(27)Entropy-Cut MH
Cut at the start of a reasoning step
we have x = 0 and y = 3.
[CUT] Step 1: Calculate r
r = sqrt(x^3 + y^3)Step 1: Calculate r
r = sqrt(x^2 + y^2)
= sqrt(0^2 + 3^2) = 3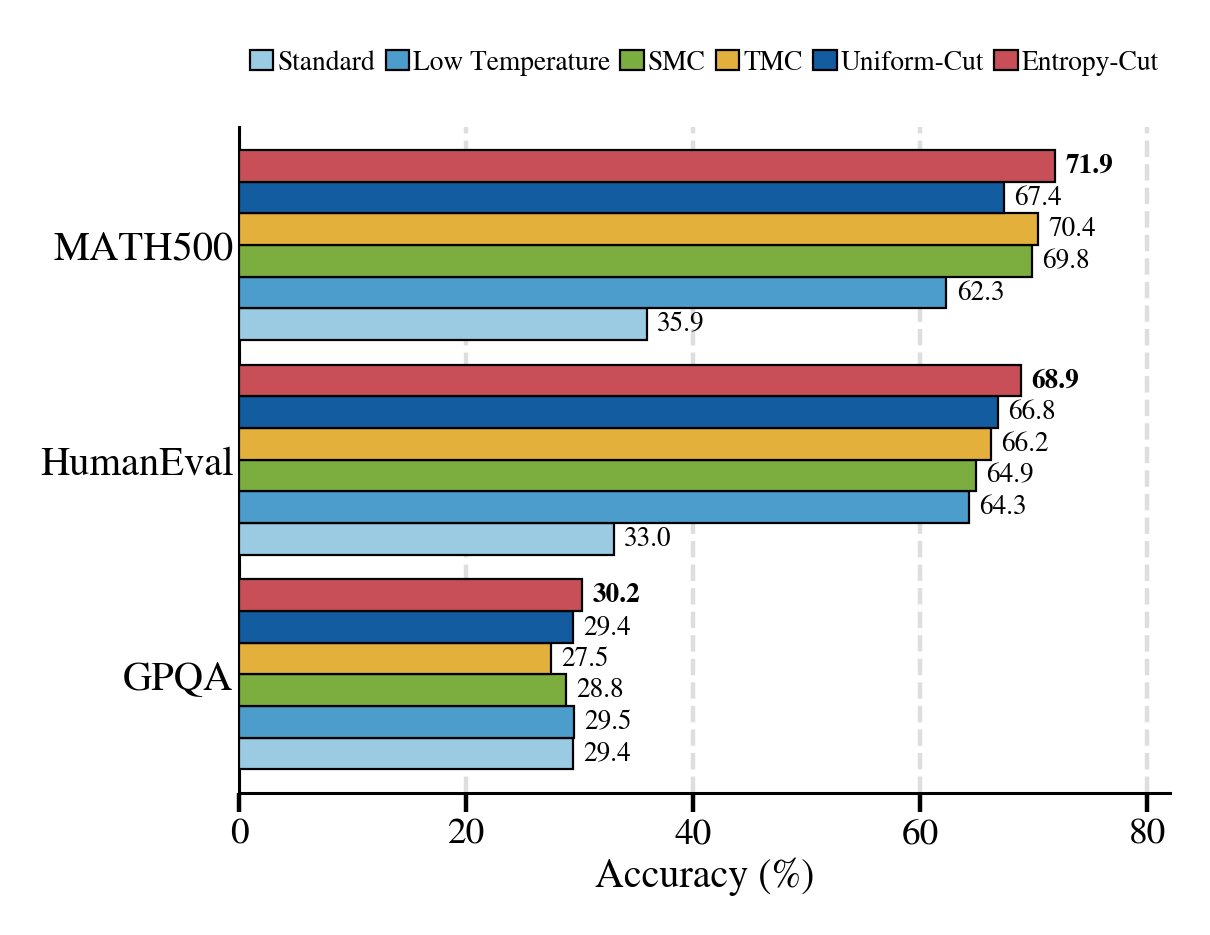
Sampling Instead of Post-Training
Frontier reasoning models are typically obtained by post-training base models with reinforcement learning. A growing body of evidence suggests that much of what RL adds is sharpening: the base model already assigns non-negligible probability to good reasoning traces, and post-training simply concentrates more mass on them. If that view is right, then sampling directly from the sharpened distribution should elicit reasoning at test time, with no additional training, datasets, or verifiers.
This is exactly what power sampling does. Given a base model p over complete traces, the power distribution
upweights traces that are already likely under p, with α > 1 controlling the sharpening. Power sampling is therefore training-free, dataset-free, and verifier-free, using only the base model's own probabilities.
The Sampling Bottleneck
For power sampling to be useful in practice, we need an efficient way to sample from ΠT. This turns out to be the main obstacle. The difficulty is that ΠT is defined over complete traces, not next-token choices. Exact sampling would require normalizing over an exponentially large sequence space. And simply lowering the per-token temperature does not recover ΠT either: sharpening at the trace level is not the same as sharpening token by token.
Karan and Du address this with a stagewise Metropolis-Hastings (MH) sampler. MH is an MCMC method that proposes candidate edits and accepts or rejects them under a rule that guarantees convergence to the target distribution. In the stagewise version, each step picks a cut position in the current trace, keeps the prefix, resamples the suffix from a proposal model, and applies the MH correction. This works, but its efficiency depends entirely on where the cut goes. With cuts placed uniformly over tokens, almost every proposal lands inside a stretch of routine continuation (mid-equation, mid-step, mid-implementation), and ends up rewriting local details rather than reopening the decisions that actually shaped the trace.
Decision Points in Reasoning Traces
To cut at decisions instead of cutting uniformly, we first need a way to identify where those decisions occur in a reasoning trace. Although a chain-of-thought may contain many tokens, only a small number of positions usually determine the subsequent reasoning path. For example, in a proof, the choice to proceed by induction rather than contradiction can determine the structure of nearly everything that follows. After that choice has been made, many later tokens are spent executing the chosen strategy. A sampler that treats every token as equally worth revising will therefore spend most of its proposals rewriting execution details rather than reopening the underlying decision.
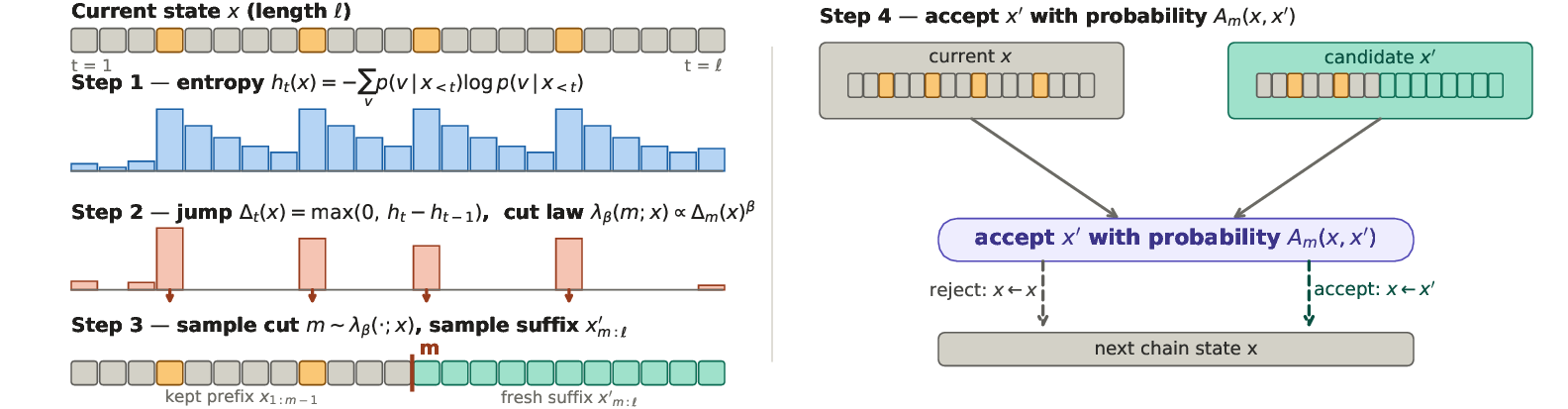
Our key observation is that positive jumps in next-token entropy are a useful proxy for decision points. A jump in entropy means that the base model has suddenly become less certain about the next token, which often happens when several qualitatively different continuations are available. Once one continuation has been chosen, the entropy can drop again as the trace moves into the execution of that choice. We test this proxy directly by taking a chain-of-thought and resampling the suffix from two kinds of cut positions: positions in the top decile of entropy jumps and positions in the bottom decile. Cuts at high-jump positions produce 1.33× the normalized edit distance and 1.36× the fraction of distinct final answers. This indicates that entropy spikes mark positions where changing the suffix is more likely to change the downstream reasoning path.
Our Algorithm: Cutting at Decision Points
The suffix-resampling experiment suggests that entropy jumps identify positions where the future reasoning path is especially sensitive to the cut. Entropy-Cut MH turns this observation into a proposal mechanism. It keeps the stagewise MH framework unchanged, but replaces the uniform cut distribution with a state-dependent distribution that gives more probability to large positive entropy jumps. At each step, given the current trace, we compute the next-token entropy profile, compute the values of positive entropy jumps Δt = max{0, ht - ht-1}, and sample a cut position with probability proportional to Δtβ. The exponent β ≥ 0 interpolates between uniform cuts (β = 0) and increasingly decision-aware cuts; we use β = 4 throughout.
Why the jump rather than the entropy itself? Because entropy often stays elevated for several tokens after a decision while its consequences are being worked out. The most informative place to cut is where uncertainty first rises.
The target distribution stays the same. Entropy-Cut MH only changes how the sampler proposes a cut; the Metropolis-Hastings acceptance rule corrects for this proposal choice, so the chain still samples from ΠT.
Uniform-Cut MH
Cut inside a local calculation
we have x = 0 and y = 3.
Step 1: Calculate r
r = sqrt(x^3 + y^3)
= sqrt(0^3 + 3^3 [CUT])} = sqrt(27)Entropy-Cut MH
Cut at the start of a reasoning step
we have x = 0 and y = 3.
[CUT] Step 1: Calculate r
r = sqrt(x^3 + y^3)Step 1: Calculate r
r = sqrt(x^2 + y^2)
= sqrt(0^2 + 3^2) = 3Uniform-Cut MH can splice into the middle of an expression, so the proposed suffix may continue with leftover syntax such as the stray brace. Entropy-Cut MH instead reopens the trace at a reasoning boundary.
Mixing-Time Analysis
Empirical gains are one thing; we would also like to understand mathematically why entropy-cutting helps. To make this precise, we analyze a stylized model of reasoning: a depth-T token-labeled tree whose root-to-leaf paths are reasoning traces. Branch nodes correspond to decision points (positions with multiple plausible continuations), and chain nodes correspond to deterministic execution.
We analyze this tree under approximate symmetry, which means two things: entropy jumps are concentrated at branch nodes, and both ΠT and the proposal distribution are close to uniform over root-to-leaf paths.
In this setting, our main theorem gives a clean separation. Let k be the number of branch nodes on a root-to-leaf path (the semantic depth) and b1 the depth of the first branch:
This separation is most meaningful when the first consequential decision appears early in the trace and only a small number of later positions are true decisions. In that regime, where b1 = O(1) and k = o(T), Entropy-Cut MH mixes in o(T) steps, while Uniform-Cut MH still needs Ω(T) steps. The theorem says that entropy-cutting can make the sampler depend on the number of semantic decisions rather than the total number of tokens.
Empirical Results
We evaluate on MATH500, HumanEval, GPQA Diamond, and AIME26 with five base and instruction-tuned models from the Qwen and Phi families, comparing against standard sampling, low-temperature sampling, SMC, TMC, and uniform-cut MH. Entropy-Cut MH matches or improves on every prior power-sampling baseline across the four benchmarks. For instance, with Qwen2.5-7B, MATH500 accuracy goes from 35.9 to 71.9, and HumanEval accuracy goes from 33.0 to 68.9.
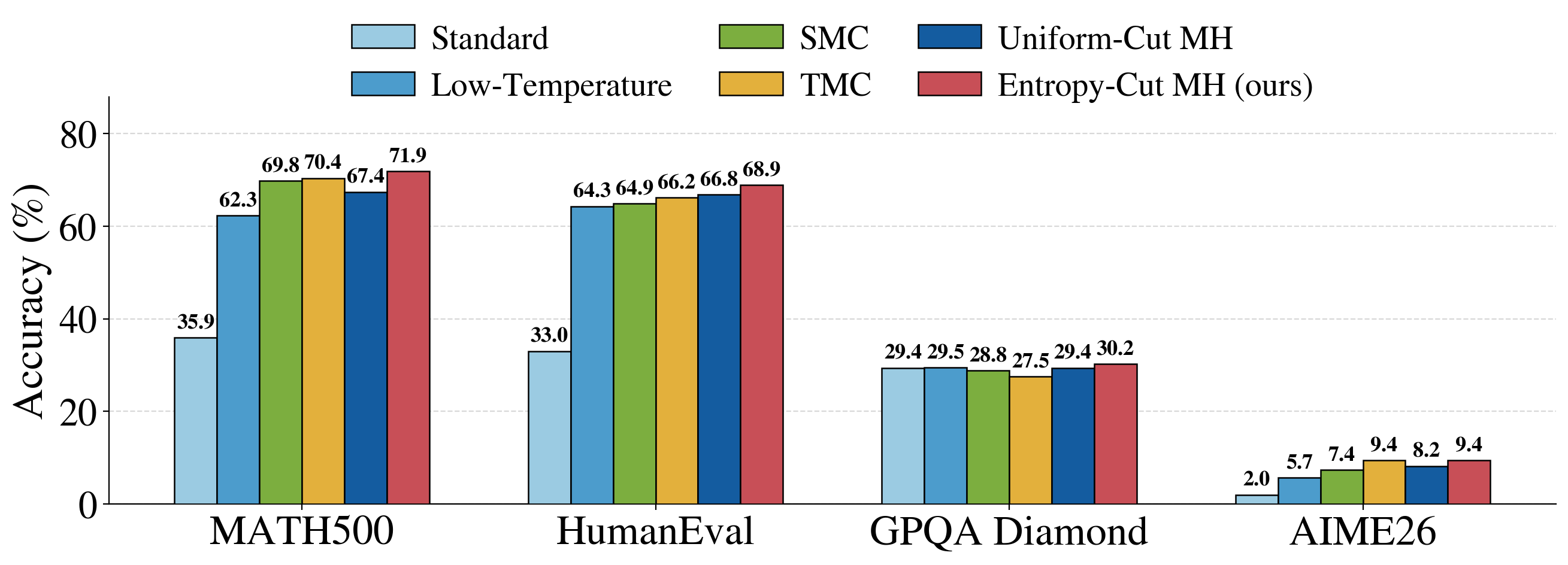
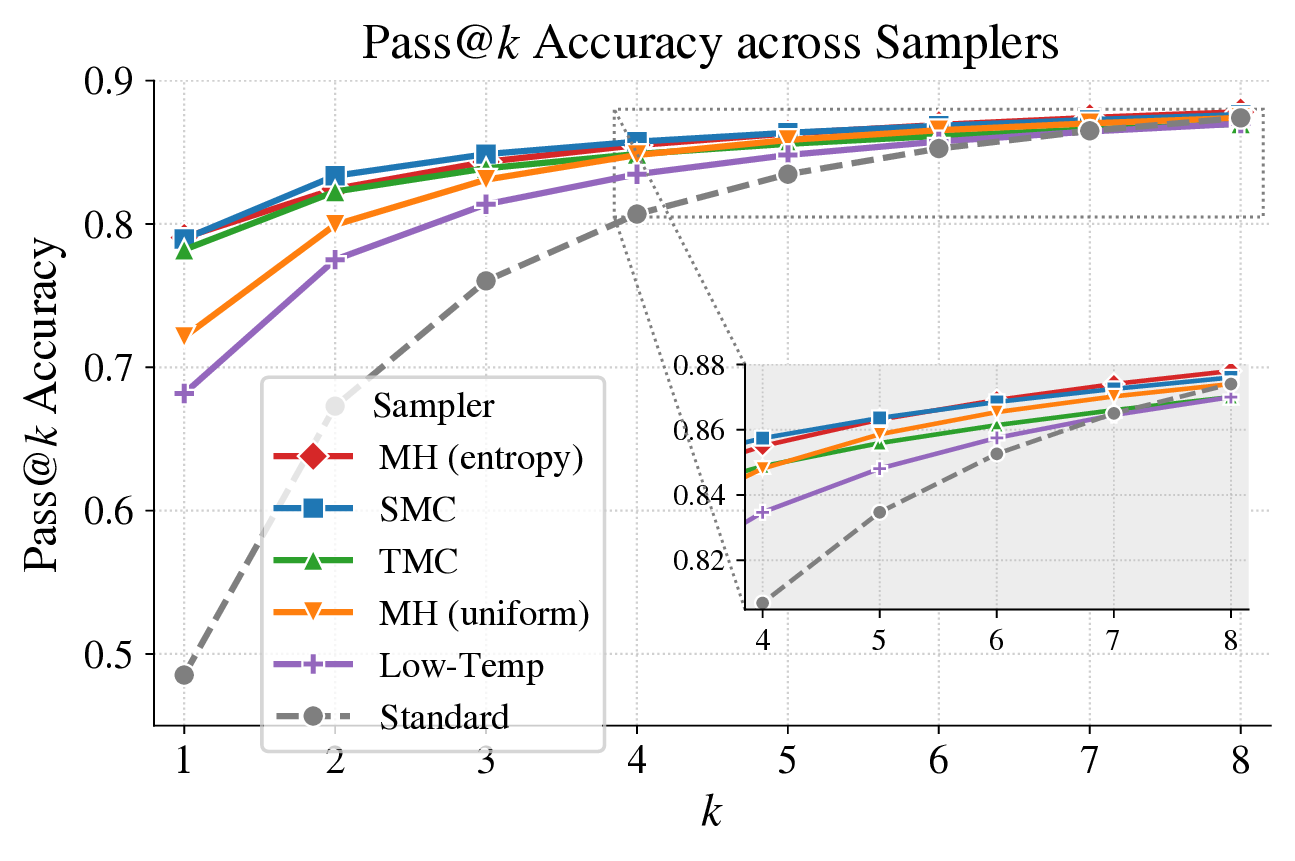
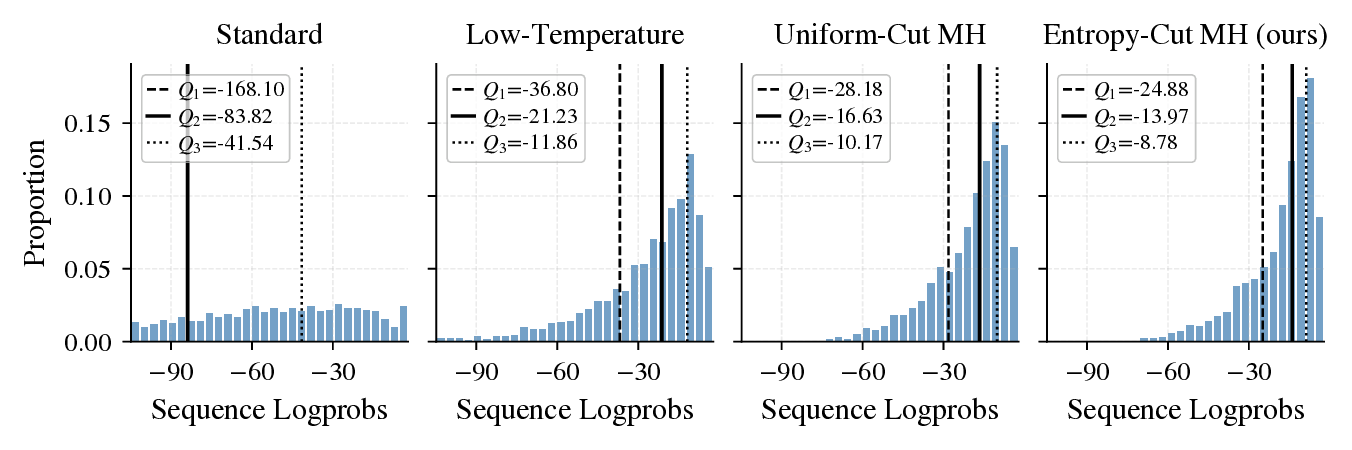
Beyond accuracy, we measure two properties of the sampler. First, samples from Entropy-Cut MH sit in higher-likelihood regions of the base model than samples from standard, low-temperature, or uniform-cut sampling. This is what we would expect if the sampler is approximating the power distribution more faithfully. Second, despite improving single-sample accuracy, the method does not collapse pass@k (the chance of getting a correct answer in k tries). Diversity is preserved, so the gains come from finding better traces rather than from concentrating on one.
Citation
@article{zhou2026reasoning,
title = {Reasoning with Sampling: Cutting at Decision Points},
author = {Zhou, Felix and Mehrotra, Anay and Liu, Quanquan C.},
journal = {arXiv preprint},
year = {2026}
}For questions, contact Felix Zhou or Anay Mehrotra.